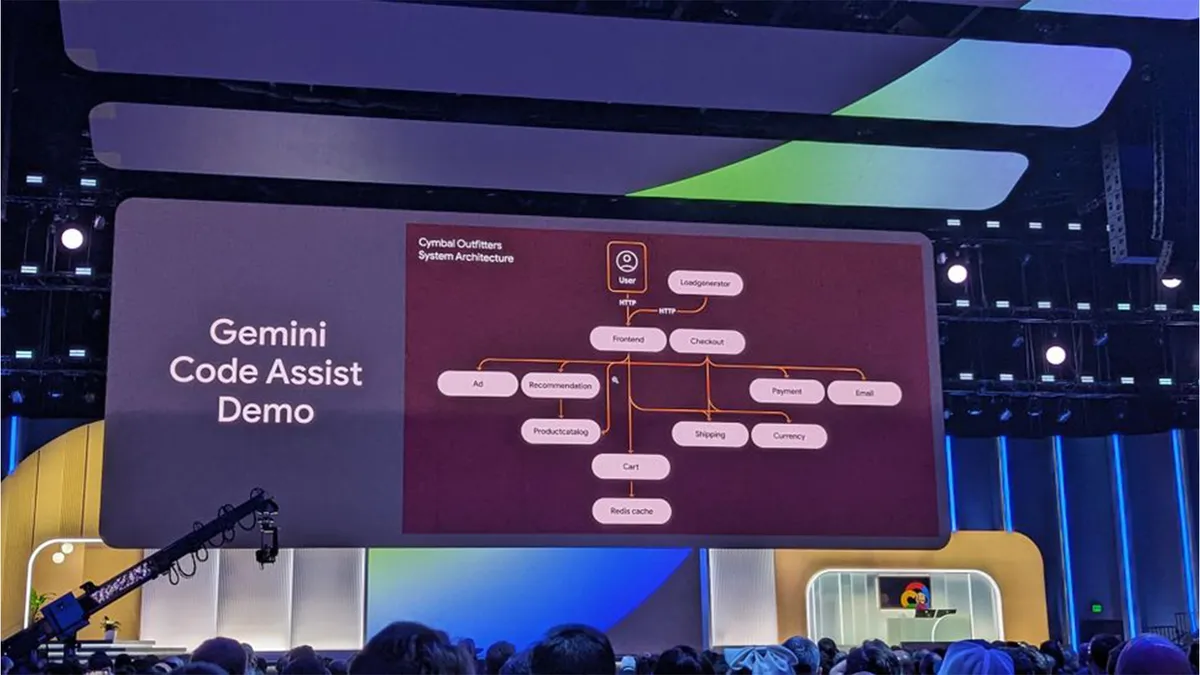
Bad bots are on the rise as almost half of all internet traffic is now automated
Web traffic is becoming dominated by automated bots, as the volume of malicious bot traffic is rising for the fifth consecutive year, but which industries are most at risk?