
The cyber threat landscape is evolving rapidly, making it extremely difficult to keep track of the myriad of rising threats and protect your organisation. Which is why it’s critical that you consider using some of the best free malware removal tools at your disposal.
Across 2022, threat actors continued to target businesses of all sizes, with ransomware and phishing attacks especially potent and effective methods employed by hackers throughout the year.
However, while larger enterprises have the financial clout to be able to invest heavily in cyber security products, many smaller businesses still struggle to find solutions that are both effective and fit within their limited budgets.
Here are six of the best free malware removal tools that could be the difference between keeping your business safe or falling victim to a potentially disastrous and costly attack
1. Avast Antivirus Free
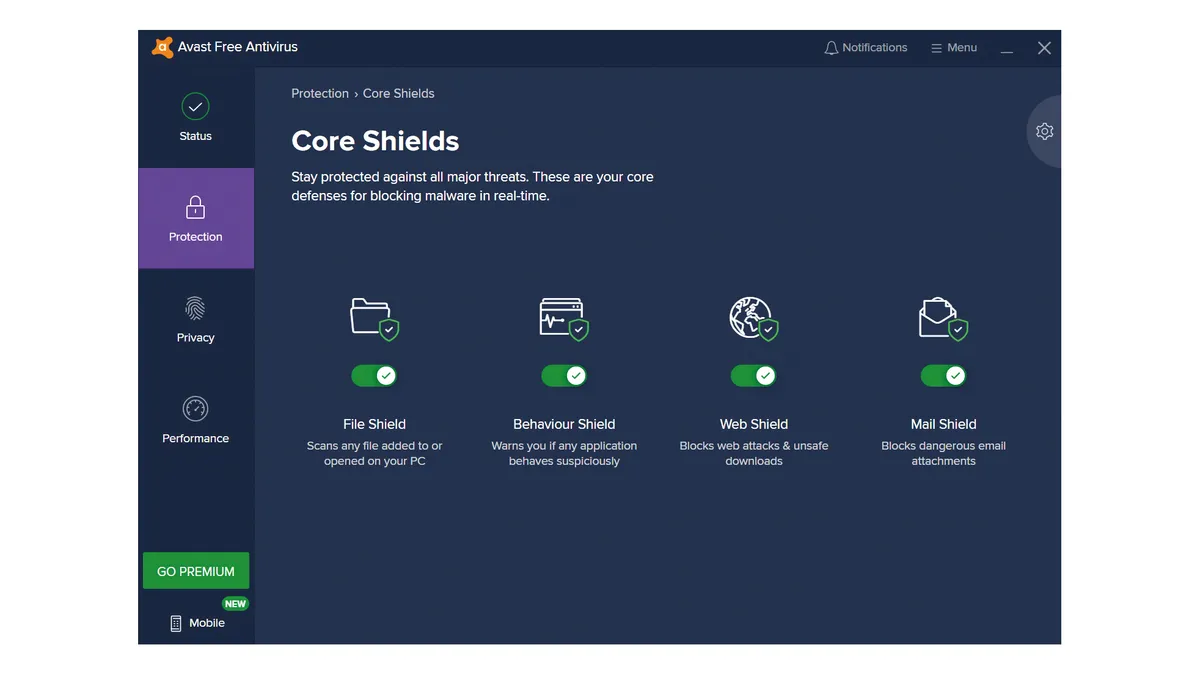
Avast's free malware protection software is among the best anti-malware tools available on the market right now.
This software provides robust malware protection, scoring 98.9% in an AV-Comparatives malware test, which is excellent for a free service and higher than many of its rivals. But Avast really comes up trumps with the wide range of extra features.
There is a variety of scanning and notification alternatives that will help you customise the tool to your own particular needs. These include a Wi-Fi scanner that detects other devices on a network you are on. This aids in discovering insecure passwords or other weaknesses. With the software installed, the tool sets off a scan of your browser to find any possible malicious extensions and installed apps.
The Hack Alert feature is handy in helping users comprehend threats outside the business, such as if your email address has been found in a data breach. This then gives forward warning to facilitate actions such as changing affected passwords or adding two factor authentication (2FA).
It also features a Ransomware Shield. This is much like Windows' built-in Controlled Folder Access feature, although the user interface is better looking. The tool thwarts malware from writing to protected locations without approval from the user.
These free features will only alert users to issues, while paying for the premium tier will ensure the software fixes these problems automatically, but as free software it still provides welcome insight into your security position. The free suite doesn’t push its premium plan that much, but you will find that tools in the paid tier are marked out visibly. This is a market-leading product when combined with other tools for preventing viruses.
For more information, read our full Avast Antivrius Free review.
2. Malwarebytes

Malwarebytes is a powerful anti-malware tool that can be leveraged to great effect and help keep your organisation safe.
This anti-malware tool is free-to-use and is available for use on Windows, macOS, ChromeOS, Android and iOS.
Malwarebytes is regularly updated to ensure you keep on top of the latest emerging strains. The platform includes real-time scanning capabilities and also has dedicated ransomware protection features, making it an ideal piece of kit for any small business.
Users opting to choose this anti-virus software will be offered a free trial of its premium service, however, upon completion of this trial period, it switches back to a basic free version. Despite this, Malwarebytes is an increasingly popular piece of software chosen by businesses and individual users alike.
This product can be downloaded here.
3. AVG AntiVirus Free


How to reduce the risk of phishing and ransomware
Top security concerns and tips for mitigation
Another great cyber security tool for business is from AVG. Its antivirus software will work quietly behind the scenes, scanning your system on a regular basis. It offers malware and performance scanning, real-time security updates, as well as malicious download protection.
There have been many changes to the software over the years as the product’s developers have made efforts to make the application simpler to operate, and worked to help users easily comprehend threats. This has been mostly effective, as the software now shows where and how it is protecting your device.
The paid version of AVG providers greater defence against downloads, data encryption, and a built-in firewall. However, the paid tier at £54.99 is a tad on the expensive side.
This product can be downloaded here.
4. Bitdefender Antivirus Free Edition

There’s no denying that Bitdefender Antivirus Free Edition lacks some of the more powerful features of the company’s paid offering, such as a password locker and advanced ransomware recovery features. But this doesn’t detract from the fact that it’s a powerful anti-malware option that has a proven track record at detecting even some of the more exotic malware strains around, and is mercifully free of advertisements.
Bitdefender Antivirus Free Edition also comes with the company’s Photon cloud-based scan system, which is designed to adapt the intensity at which it uses resources to match a device’s capabilities. This could prove extremely useful if one is seeking a powerful tool for removing malware, but don’t want to sacrifice too much performance.
This free version works on computers running Windows 7 to Windows 11. There is also an app for computers running MacOS (this requires at least macOS 10), as well as apps for Android phones and tablets.
This product can be downloaded here.
5. Microsoft Defender

Now the default anti-virus and anti-malware product for all box-fresh Windows machines, Microsoft Defender has come on leaps and bounds since the Windows Defender and Microsoft Security Essentials (MSE) days of Windows 7. Microsoft’s built-in anti-virus product has previously been seen as a decently serviceable default option, but middling performance has always given third-party manufacturers opportunities on which to capitalise in the anti-virus market. It has always been the protection you use until you can get something more powerful - the Microsoft Edge of anti-malware, if you will.
It’s only in the past few years that Microsoft Defender - its current name - has been viewed as a serious protector in the cyber security space. Perhaps only let down by an unwelcoming user interface (UI), Microsoft Defender offers highly accurate, comprehensive protection from cyber security threats from the moment you first power-on your device.
Windows Defender version 4.18 performed impressively in AV-test rankings, scoring a 100% detection rate for widespread and prevalent malware discovered in the last four weeks (as of December 2022). What’s more, it’s absolutely free to use, everyone who runs a Windows PC has it, and it’s automatically updated regularly to combat against new and emerging threats.
Microsoft Defender comes pre-installed on Windows 10 and Windows 11, and you can download MSRT here.
Read our full Microsoft Defender review for more information.
6. Panda Free Antivirus

Available to download here.
As a cloud-based anti-malware software, Panda Free Antivirus could be perfect for those seeking a less resource-intensive fix. Unlike some of the other solutions, which can take up an unwelcome amount of memory during scans (and even passively in the system tray), Panda leverages most of the work on its servers. This frees one up to perform intensive tasks while scans are performed, without either competing for memory or storage allocation.
Panda Free Antivirus can also operate as a virtual private network (VPN) and is capable of file encryption, password management, and system recovery in the case of catastrophically-compromised devices that won’t even boot.








